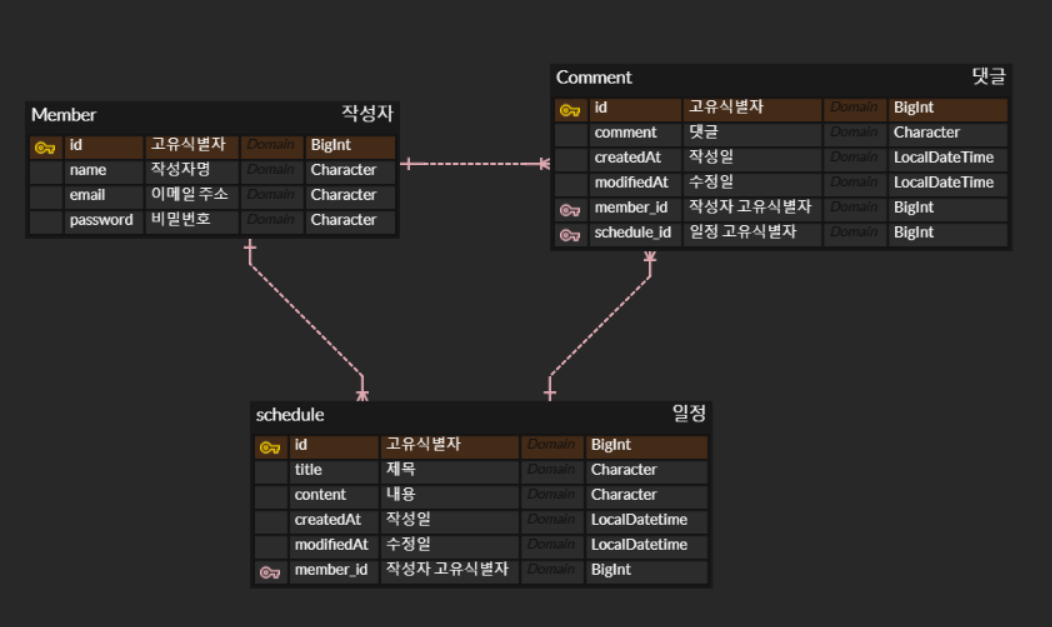
일정 관리 앱의 마지막 단계는 schedule 조회 시 Pagination 이었다
나는 schedule 고유식별자에 따라 "/comment" 주소를 만들어 선택 schedule과 schedule id를 가진 comment 값을 리턴하도록 했다
이때 사용 가능한 방법이 두 가지 였다
1. JOIN문을 사용하여 comment를 모두 가져오는 것
2. schedule에 부분적으로 comment의 정보를 저장해서 schedule만 가져오는 것
1번은 정규화 데이터베이스를 사용하는 방법, 2번은 비정규화 데이터베이스를 사용하는 방법이다
오늘 나는 이 두 개념과 내가 선택한 방법에 대해 알아보고자 한다
정규화(Normalized)는 관계형 데이터베이스에서 중복을 최소화하기 위해 데이터를 구조화하는 작업이다
또한 하나의 종속성이 하나의 relation에 표현될 수 있도록 분해해가는 과정이다
한 relation에 여러 Entity의 Attribute 들을 혼합하게 되면 정보가 중복 저장되며, 저장 공간을 낭비하게 된다
또한 중복된 정보로 인해 갱신 이상(Modification Anomaly)이 발생하게 된다
동일한 정보를 한 relation에는 변경하고, 나머지 relation에서는 변경하지 않은 경우 어느 것이 정확한지 알 수 없게 된다
정규화의 원칙
1. 정보의 무손실 표현
하나의 스키마를 다른 스키마로 변환할 때 정보의 손실이 있어서는 안된다
2. 분리의 원칙
하나의 독립된 관계성은 하나의 독립된 relation으로 분리시켜 표현해야한다
3. 데이터의 중복성이 감소되어야한다
함수적 종속(Functional Dependency)은 데이터들이 어떤 기준 값에 의해 종속되는 것을 말한다
완전 함수적 종속은 어떤 속성이 기본키에 대해 완전히 종속적일 때를 말한다
부분 함수적 종속은 어떤 테이블 R에서 속성 A가 다른 속성 집합 B 전체에 대해 함수적 종속이면서 속성집합 B의 어떠한 진부분 집합에도 함수적 종속일 때 A가 속성 집합 B에 부분 함수적 종속이라고 한다
정규화 데이터베이스(normalized database)은 중복을 최소화하도록 설계된 데이터베이스이다
정규형은 특정 조건을 만족하는 relation의 스키마 형태이다
스키마는 데이터베이스의 논리적 구조와 제약 조건을 정의하는 설계도이다
정규형의 형태로는 제 1 정규형, 제 2 정규형, 제 3 정규형, BCNF형, 제 4 정규형, 제 5 정규형이 존재한다
차수가 높아질 수록 만족시켜야 할 제약 조건이 늘어난다

정규화 과정
1. 제 1정규형(1NF)
테이블의 모든 칼럼이 원자값(Atomic Value)을 가져야 한다
하나의 컬럼에 여러개의 값이 들어가면 안 된다
2. 제 2정규형(2NF)
부분적 함수 종속성 제거한다
기본 키의 일부에만 종속된 속성을 제거한다
복합 키를 사용할 때, 특정 키에만 의존하는 컬럼이 있으면 별도 테이블로 분리한다
3. 제 3정규형(3NF)
이행적 함수 종속성을 제거한다(A -> B, B - > C 관계가 있을 때 A -> C가 되지 않도록 한다)
PK가 아닌 컬럼이 다른 PK가 아닌 컬럼을 결정하지 않아야 한다
4. BCNF(Boyce-Codd 정규형)
3NF에서 여전히 일부 결정자가 후보 키가 아닐 때, 이를 해결하기 위해 사용한다
정규화가 이루어질 경우 장점은 아래와 같다
데이터베이스 변경시 이상현상(anomaly)을 제거한다
데이터의 중복을 감소시켜 저장 공간을 최소화한다
효과적인 검색 알고리즘 생성이 가능하다
데이터 삽입 시 relation 재구성의 필요성이 감소된다
데어터 구조의 안정성 및 무결성을 유지해 한 곳에서만 수정하게 한다
정규화가 아루어질 경우의 단점은 아래와 같다
relation 간의 JOIN 연산이 증가하며 따라서 복잡한 쿼리가 발생한다
질의에 대한 응답 시간이 증가해 성능이 저하된다
비정규화(Denormalization)는 성능 최적화와 빠른 데이터 접근을 위해 정규화된 테이블을 다시 합치는 과정이다
데이터를 일부 중복 저장해 읽기 속도를 향상시킨다
*데이터베이스 최적화(Optimization)는 데이터의 저장, 검색, 수정 삭제 등의 작업을 더 빠르고 효율적으로 수행할 수 있도록 데이터베이스 성능을 개선하는 과정을 말한다
비정규화 방법은 아래와 같다
자주 사용하는 조회 데이터를 합친 테이블을 생성한다
조인을 줄이기 위해 중복 데이터를 허용한다
테이블을 병합해 데이터 검색 속도를 향상시킨다
비정규화 데이터베이스(denormalized database)는 읽는 시간을 최적화하도록 설계된 데이터베이스이다
RDB를 사용하는 경우 Join 연산의 비용을 줄일 수 있다
높은 규모 확장성을 실현하기 위해 자주 사용되는 기법이다
하나 이상의 테이블에 데이터를 중복해 배치하는 최적화 기법이다
시스템의 성능 향상, 개발 및 운영의 편의성 등을 위해 정규화된 데이터 모델을 통합, 중복, 분리하는 과정
의도적으로 정규화 원칙을 위배하는 행위이다
비정규화가 이루어질 경우 장점은 아래와 같다
조인을 하지 않아 데이터를 빠르게 조회할 수 있다
살펴볼 테이블이 줄어들기 때문에 데이터 조회 쿼리가 간단해진다
따라서 오류 발생 가능성도 줄어든다
비정규화가 이루어질 경우의 단점은 아래와 같다
데이터 갱신이나 삽입 비용이 높다
데이터 갱신 또는 삽입 코드를 작성하기 어려워진다
데이터 간의 일관성(consistency)이 깨질 수 있다
데이터를 중복하여 저장하므로 더 많은 저장 공간이 필요하다
비정규화를 할 경우 단점도 분명히 존재할 수 있기 때문에 다음의 경우에만 비정규화를 고려해야한다
비정규화의 대상이 될 경우
1. 자주 사용되는 테이블에 엑세스하는 프로세스의 수가 가장 많고 항상 일정한 범위만을 조회하는 경우
2. 테이블에 대량 데이터가 있고 대량의 범위를 자주 처리하는 경우에 성능 상의 이슈가 있을 경우
3. 테이블에 지나치게 조인을 많이 사용하게 되어 데이터를 조회하는 것이 기술적으로 어려울 경우
규모 확장성(scalability)를 요구하는 시스템의 경우 거의 항상 정규화된 데이터베이스와 비정규화된 데이터베이스를 섞어 사용한다
이상현상(Anomaly)은 중복된 정보로 인해 발생하는 문제들을 말한다
정규화를 통해 방지할 수 있다
삽입 이상(Insertion Anomaly)은 원하지 않는 자료가 삽입된다든지, 삽입하는데 자료가 부족해 삽입이 되지 않아 발생하는 문제점이다
삭제 이상(Deletion Anomaly)은 하나의 자료만 삭제하고 싶지만, 그 자료가 표함된 튜플 전체가 삭제됨으로 원하지 않는 정보 손실이 발생하는 문제점이다
갱신 이상(Modification Anomaly)은 정확하지 않거나 일부의 튜플만 갱신되어 정보가 모호해지거나 일관성이 없어져 정확한 정보 파악이 되지 않는 문제점
아래는 기존 나의 일정 Service 클래스이다
일정을 하나 조회할 때 일정에 달린 댓글을 모두 가져오고자 했다
public class ScheduleService {
private final CommentRepository commentRepository;
private final ScheduleRepository scheduleRepository;
//일정 id 에 따라 댓글 모두 가져오기
public Page<Comment> getComments(Long scheduleId, Pageable pageable) {
return commentRepository.findAllByScheduleIdOrElseThrow(scheduleId, pageable);
}
// 일정 id로 일정 조회
public ScheduleResponseDto findScheduleById(Long id) {
Schedule schedule = scheduleRepository.findScheduleByIdOrElseThrow(id);
return ScheduleResponseDto.toDto(schedule);
}
}
따라서 Comment 테이블에서 ScheduleId 값을 가진 comment를 모두 가져와 확인하려고 했다
아래와 같은 메소드를 사용하고자 했는데 사실 comment 자체 값은 필요하지 않았다
public interface CommentRepository extends JPA Repiository<Comment, Long> {
Optional<Page<Comment>> findAllByScheduleId(Long scheduleId, Pageable pageable);
default Page<Comment> findAllByScheduleIdOrElseThrow(Long scheduleId, Pageable pageable) {
return findAllByScheduleId(scheduleId, pageable)
.orElseThrow(() -> new ApplicationException(ErrorMessageCode.NOT_FOUND, "Comment Not Found"));
}
}
또한 요구 사항은 다음과 같았다

요구사항을 JPQL 로 작성하되, 비정규화 방법을 사용하고자 했다
그러나 일정 작성자명이 필요하다보니 Member 정보가 필요해서 Member와 JOIN하는 Query문도 작성하게 되었다
아래는 schedule 과 member 를 조회하고 DTO에 넣어서 수정일 기준 내림차순 정렬하는 쿼리문을 DB로 보내는 메서드이다
public interface ScheduleRepository extends JPARepository<Schedule, Long> {
@Query("SELECT new com.example.SchedulingApp.Developed.domain.schedule.dto.PageScheduleResponseDto(s.title, s.content, s.commentCount, m.name, s.createdAt, s.modifiedAt)" +
"FROM Schedule s JOIN Member m ON s.member.id = m.id " +
"WHERE s.id = :scheduleId " +
"ORDER BY s.modifiedAt DESC")
Page<PageScheduleResponseDto> findAllByOrderByScheduleIdModifiedAtDesc(Long scheduleId, Pageable pageable);
}
완전하게 정규화된 방법, 비정규화된 방법이라고 할 수 없지만 두 방식에 대해 알아보고 데이터베이스 최적화를 위해 내 나름 최선을 다한 데에 의의가 있다고 생각한다
다음에 이러한 문제가 다시 생긴다면 보다 편하게 해답을 캐치하고 해결할 수 있을 것이다
오늘 고생하고 노력한만큼 내일 더 잘 할 수 있을 것이다
화이팅 !
https://github.com/Hokirby/Scheduler
GitHub - Hokirby/Scheduler
Contribute to Hokirby/Scheduler development by creating an account on GitHub.
github.com
'[Kotlin&Spring] 5기 내일배움캠프' 카테고리의 다른 글
| [Kotlin&Spring] 5기 JPA 연관 관계 매핑과 N+1 문제 (1) | 2025.02.24 |
|---|---|
| [Kotlin&Spring] 5기 운영체제에서 출발한 동기화 문제와 DB 로딩 전략 (0) | 2025.02.13 |
| [Kotlin&Spring] 5기 컴파일 방식들과 자바의 컴파일 (1) | 2025.02.11 |
| [Kotlin&Spring] 5기 Java Reflection에 대해 - JPA (0) | 2025.02.10 |
| [Kotlin&Spring] 5기 운영체제의 개념을 알아보자 (1) | 2025.02.07 |


